用归一化方法来降低深度学习的过拟合问题

墨家总院
31人赞赏了该文章
698次浏览
编辑于2018年12月04日 20:06:19
(本文独家发布在金蝶云社区上)
我们为什么需要归一化
随着深度神经网络变得越来越复杂,系统不可避免地将出现过度拟合的问题。 因此,我们需要一些技巧来克服过拟合的问题。解决这个问题的解决方案之一是进行规一化(Regularization)。现在已经有几种正则化方法了,本文将讨论最一般最简单的一种方法。
如何进行归一化操作
正规化听起来非常高贵和神秘,但它只是在原来的成本函数添加的一个附加项目。那么让我们回顾一下没有规一化的成本函数:
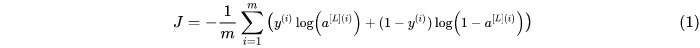
然后我们再看一下有了归一化操作的成本函数:

在这个大家伙里,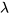 叫做归一化参数(regularization parameter),很明显它是一种超参数。即不一样的 值将会生成不一样的模型。
叫做归一化参数(regularization parameter),很明显它是一种超参数。即不一样的 值将会生成不一样的模型。
归一化操作对梯度下降法的影响
在深度学习中,梯度下降法通常用于找到最优参数矩阵:W。我们首先回顾一些参数矩阵W上的梯度下降计算公式:
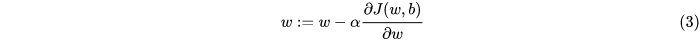
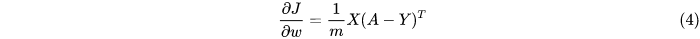
如果我们想要对新版本的成本函数求导数,新的偏导数是这样的:
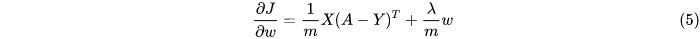
现在我们把式子5放到式子3里,我们得到:
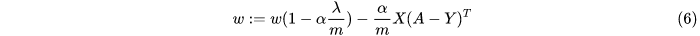
从式子得知, 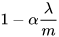 是小于1的,因此W的最终值将会比之前更小(没有做归一化的时候)。如果 变得越大,W也会相应的变得越小。
是小于1的,因此W的最终值将会比之前更小(没有做归一化的时候)。如果 变得越大,W也会相应的变得越小。
为什么归一化操作能够减少过拟合问题
为了直观地回答这个问题,我们从一个基本问题开始:我们训练的机器学习模型只有三种情况:“高偏差”,“正好” 和 “高方差”。

我们的目标是“正好”,归一化方法是用来减少第三类情况的发生:“高方差”。
根据上一节的推论, 变大,最终的W会变小。如果 变得足够大,W的值将接近零。这意味着整个网络变成了一个非常简单的网络,如Logistic回归一样简单,因为大多数网络权重变为0。因此我们可以找到一个 的中间值来获得“正好”的情况。
31人点赞
还没有人点赞,快来当第一个点赞的人吧!
0人打赏
还没有人打赏,快来当第一个打赏的人吧!
