
一.系统环境
本文主要基于Kubernetes1.23.1和Linux操作系统CentOS7.4。
| 服务器版本 | docker软件版本 | Kubernetes(k8s)集群版本 | CPU架构 |
|---|---|---|---|
| CentOS Linux release 7.4.1708 (Core) | Docker version 20.10.14 | v1.23.1 | x86_64 |
Kubernetes高可用集群总体架构图:
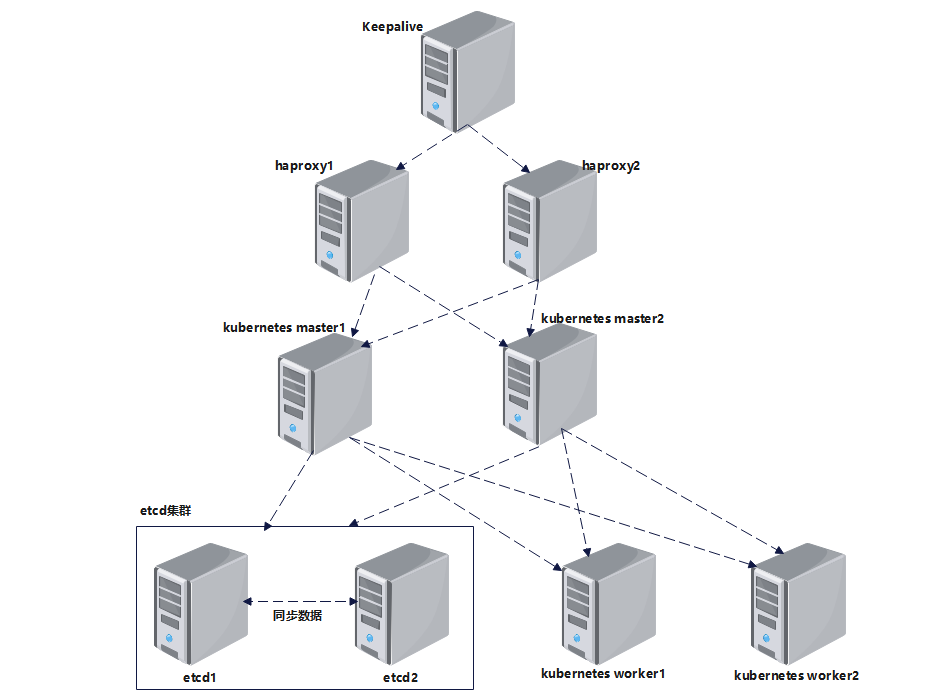
Kubernetes高可用集群架构图描述:
Kubernetes(k8s)配置文件是放在etcd集群里的,2个Kubernetes master节点都连接到etcd集群,就可以保证Kubernetes的master节点
数据同步,信息对等,我们刚开始是连接到Kubernetes的master1上的,master1出现故障之后,还需要手动切换连接到master2上,我
们可以使用haproxy做负载均衡器,我们连接到haproxy后,haproxy会把请求转发到后端realserver(master1和master2),master1故
障之后,haproxy检测到master1故障,会把请求转发给master2,如果害怕haproxy故障,可以使用Keepalive做haproxy的高可用,我
们连接Keepalive的VIP即可。
由于机器有限,我们本次Kubernetes高可用集群架构图如下:
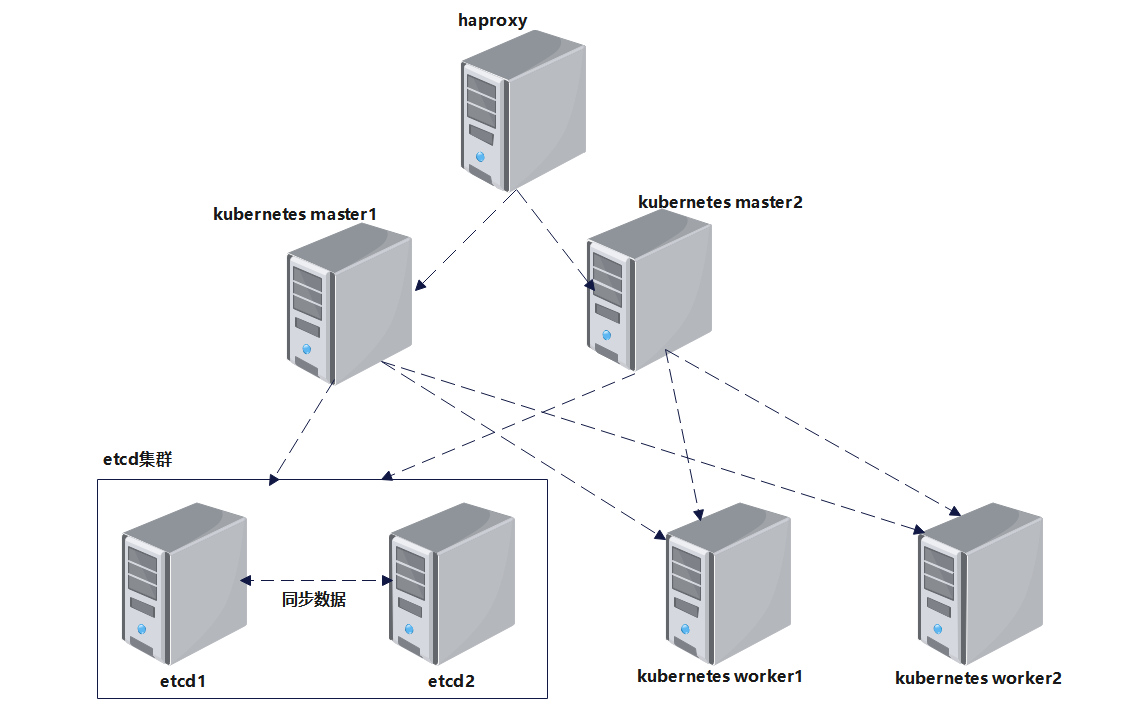
Kubernetes高可用集群架构:k8sbalancemaster1作为master1节点,k8sbalancemaster2作为master2节点,k8sbalanceworker1作为worker节点,k8sbalanceetcd1作为etcd服务器,k8sbalanceetcd2作为etcd服务器,k8sbalancehaproxy1作为HAProxy服务器。
| 服务器 | 操作系统版本 | CPU架构 | 进程 | 功能描述 |
|---|---|---|---|---|
| k8sbalancehaproxy1/192.168.110.134 | CentOS Linux release 7.4.1708 (Core) | x86_64 | haproxy | HAProxy负载均衡器 |
| k8sbalanceetcd1/192.168.110.135 | CentOS Linux release 7.4.1708 (Core) | x86_64 | etcd | etcd服务器 |
| k8sbalanceetcd2/192.168.110.136 | CentOS Linux release 7.4.1708 (Core) | x86_64 | etcd | etcd服务器 |
| k8sbalancemaster1/192.168.110.137 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kube-apiserver,kube-scheduler,kube-controller-manager,kubelet,kube-proxy,coredns,calico | k8s master1节点 |
| k8sbalancemaster2/192.168.110.138 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kube-apiserver,kube-scheduler,kube-controller-manager,kubelet,kube-proxy,coredns,calico | k8s master2节点 |
| k8sbalanceworker1/192.168.110.139 | CentOS Linux release 7.4.1708 (Core) | x86_64 | docker,kubelet,kube-proxy,calico | k8s worker节点 |
二.前言
Kubernetes是一个开源的容器编排平台,用于自动化地部署、扩展和管理容器化应用程序。在生产环境中,为了确保集群的高可用性,我们需要使用多个Master节点来实现冗余和故障切换。
关于Kubernetes(k8s)单master集群的安装部署,可以查看博客《Centos7 安装部署Kubernetes(k8s)集群》https://www.cnblogs.com/renshengdezheli/p/16686769.html。
三.Kubernetes(k8s)高可用简介
Kubernetes高可用集群由多个Master节点组成,每个Master节点都能够处理用户请求并执行相关操作。当任一Master节点发生故障时,其他节点可以接管其职责,从而保证整个集群的稳定运行。
本文将使用以下主要步骤来实现Kubernetes高可用集群:
准备环境:安装所需的软件包和依赖项。
配置负载均衡器:设置负载均衡器以实现流量的分发和故障切换。
配置etcd集群:etcd集群存储k8s的配置文件和集群信息。
初始化Master节点:选择一台Master节点,并进行初始化设置。
添加额外的Master节点:将其他Master节点加入到集群中。
添加worker节点:将worker节点加入到集群中。
部署CNI网络插件calico:calico用于节点间的通信和配置网络策略。
测试Kubernetes(k8s)的master节点数据同步。
测试Kubernetes(k8s)集群的高可用。
四.配置机器基本环境
本次Kubernetes高可用集群共6台机器,我们先把6台机器都配置好基本环境,后面部署应用才会顺风顺水。
先配置各个节点的基本环境,6个节点都要同时设置,在此以k8sbalancehaproxy1节点作为示例。
首先设置主机名。
[root@localhost ~]# vim /etc/hostname[root@localhost ~]# cat /etc/hostnamek8sbalancehaproxy1
查看默认的IP地址。
[root@localhost ~]# ifconfigens32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.110.134 netmask 255.255.255.0 broadcast 192.168.110.255 inet6 fe80::20c:29ff:fe09:7e88 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:09:7e:88 txqueuelen 1000 (Ethernet) RX packets 11476 bytes 4296221 (4.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 9366 bytes 6197543 (5.9 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1 (Local Loopback) RX packets 4020 bytes 239760 (234.1 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 4020 bytes 239760 (234.1 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
配置节点IP地址(可选),网卡配置详解,请查看博客《centos 7网卡配置文件详解(ifcfg-ens33)》。
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens32TYPE=EthernetBOOTPROTO=staticNAME=ens32DEVICE=ens32ONBOOT=yesDNS1=114.114.114.114IPADDR=192.168.110.134NETMASK=255.255.255.0GATEWAY=192.168.110.2ZONE=trusted
重启网络。
[root@localhost ~]# service network restartRestarting network (via systemctl): [ 确定 ][root@localhost ~]# systemctl restart NetworkManager
重启机器之后,主机名变为k8sbalancehaproxy1。
测试机器是否可以访问网络。
[root@k8sbalancehaproxy1 ~]# ping www.baidu.comPING www.a.shifen.com (14.215.177.39) 56(84) bytes of data.64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=34.1 ms64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=34.2 ms64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=3 ttl=128 time=41.9 ms ^C --- www.a.shifen.com ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 34.123/36.765/41.958/3.672 ms
配置IP和主机名映射,其他节点的/etc/hosts文件内容也要一样。
[root@k8sbalancehaproxy1 ~]# vim /etc/hosts[root@k8sbalancehaproxy1 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.110.134 k8sbalancehaproxy1192.168.110.135 k8sbalanceetcd1192.168.110.136 k8sbalanceetcd2192.168.110.137 k8sbalancemaster1192.168.110.138 k8sbalancemaster2192.168.110.139 k8sbalanceworker1
可以ping通其他5个节点则成功。
[root@k8sbalancehaproxy1 ~]# ping k8sbalancehaproxy1PING k8sbalancehaproxy1 (192.168.110.134) 56(84) bytes of data.64 bytes from k8sbalancehaproxy1 (192.168.110.134): icmp_seq=1 ttl=64 time=0.041 ms64 bytes from k8sbalancehaproxy1 (192.168.110.134): icmp_seq=2 ttl=64 time=0.034 ms64 bytes from k8sbalancehaproxy1 (192.168.110.134): icmp_seq=3 ttl=64 time=0.023 ms ^C --- k8sbalancehaproxy1 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.023/0.032/0.041/0.009 ms[root@k8sbalancehaproxy1 ~]# ping k8sbalanceetcd1PING k8sbalanceetcd1 (192.168.110.135) 56(84) bytes of data.64 bytes from k8sbalanceetcd1 (192.168.110.135): icmp_seq=1 ttl=64 time=0.606 ms64 bytes from k8sbalanceetcd1 (192.168.110.135): icmp_seq=2 ttl=64 time=0.438 ms ^C --- k8sbalanceetcd1 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.438/0.522/0.606/0.084 ms[root@k8sbalancehaproxy1 ~]# ping k8sbalanceetcd2[root@k8sbalancehaproxy1 ~]# ping k8sbalancemaster1[root@k8sbalancehaproxy1 ~]# ping k8sbalancemaster2[root@k8sbalancehaproxy1 ~]# ping k8sbalanceworker1
关闭屏保。
[root@k8sbalancehaproxy1 ~]# setterm -blank 0
下载新的yum源。
[root@k8sbalancehaproxy1 ~]# rm -rf /etc/yum.repos.d/* ;wget ftp://ftp.rhce.cc/k8s/* -P /etc/yum.repos.d/--2022-04-09 17:48:37-- ftp://ftp.rhce.cc/k8s/* => “/etc/yum.repos.d/.listing” 正在解析主机 ftp.rhce.cc (ftp.rhce.cc)... 101.37.152.41 正在连接 ftp.rhce.cc (ftp.rhce.cc)|101.37.152.41|:21... 已连接。 正在以 anonymous 登录 ... 登录成功!......100%[=======================================================================================================================================================================>] 276 --.-K/s 用时 0s 2022-04-09 17:48:40 (81.9 MB/s) - “/etc/yum.repos.d/k8s.repo” 已保存 [276]
新的repo文件如下。
[root@k8sbalancehaproxy1 ~]# ls /etc/yum.repos.d/CentOS-Base.repo docker-ce.repo epel.repo k8s.repo
关闭selinux,设置SELINUX=disabled。
[root@k8sbalancehaproxy1 ~]# vim /etc/selinux/config[root@k8sbalancehaproxy1 ~]# cat /etc/selinux/config# This file controls the state of SELinux on the system.# SELINUX= can take one of these three values:# enforcing - SELinux security policy is enforced.# permissive - SELinux prints warnings instead of enforcing.# disabled - No SELinux policy is loaded.SELINUX=disabled# SELINUXTYPE= can take one of three two values:# targeted - Targeted processes are protected,# minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection.SELINUXTYPE=targeted [root@k8sbalancehaproxy1 ~]# getenforceDisabled
配置防火墙允许所有数据包通过。
[root@k8sbalancehaproxy1 ~]# firewall-cmd --set-default-zone=trustedWarning: ZONE_ALREADY_SET: trusted success[root@k8sbalancehaproxy1 ~]# firewall-cmd --get-default-zonetrusted
Linux swapoff命令用于关闭系统交换分区(swap area),如果不关闭swap,就会在kubeadm初始化Kubernetes的时候报错:“[ERROR Swap]: running with swap on is not supported. Please disable swap”。
[root@k8sbalancehaproxy1 ~]# swapoff -a ;sed -i '/swap/d' /etc/fstab[root@k8sbalancehaproxy1 ~]# cat /etc/fstab## /etc/fstab# Created by anaconda on Thu Oct 18 23:09:54 2018## Accessible filesystems, by reference, are maintained under '/dev/disk'# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info#UUID=9875fa5e-2eea-4fcc-a83e-5528c7d0f6a5 / xfs defaults 0 0
五.部署haproxy负载均衡器
haproxy作为负载均衡器,现在部署haproxy。
安装haproxy。
[root@k8sbalancehaproxy1 ~]# yum -y install haproxy [root@k8sbalancehaproxy1 ~]# rpm -qa | grep haproxyhaproxy-1.5.18-9.el7_9.1.x86_64
修改haproxy配置文件/etc/haproxy/haproxy.cfg。
[root@k8sbalancehaproxy1 ~]# ls /etc/haproxy/haproxy.cfg[root@k8sbalancehaproxy1 ~]# vim /etc/haproxy/haproxy.cfg[root@k8sbalancehaproxy1 ~]# tail -10 /etc/haproxy/haproxy.cfg#k8s-masterlb这个名字可以随意起,*:6443表示监听6443端口,当有人通过haproxy访问6443端口#把请求转发给后端的real server(k8s的master节点) weight 1权重都是1listen k8s-masterlb *:6443 mode tcp #balance roundrobin表示轮询调度 balance roundrobin #s1 s2 为k8s的两个master节点IP,weight都为1表示权重一样 server s1 192.168.110.137:6443 weight 1 server s2 192.168.110.138:6443 weight 1
设置haproxy开机自启动,现在启动haproxy。
[root@k8sbalancehaproxy1 ~]# systemctl enable haproxy --now[root@k8sbalancehaproxy1 ~]# systemctl is-active haproxyactive[root@k8sbalancehaproxy1 ~]# systemctl status haproxy● haproxy.service - HAProxy Load Balancer Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled) Active: active (running) since 六 2022-04-09 11:33:21 CST; 6h ago Main PID: 958 (haproxy-systemd) CGroup: /system.slice/haproxy.service ├─958 /usr/sbin/haproxy-systemd-wrapper -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid ├─963 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds └─964 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -Ds
查看端口,已经开始监听6443端口了。
[root@k8sbalancehaproxy1 ~]# netstat -antup | grep 6443tcp 0 0 0.0.0.0:6443 0.0.0.0:* LISTEN 964/haproxy
六.部署etcd集群
此次etcd集群只有两个etcd节点,关于etcd单节点配置,etcd三节点配置,更详细的内容,请查看博客《Kubernetes后台数据库etcd:安装部署etcd集群,数据备份与恢复》。
安装etcd。
[root@k8sbalanceetcd1 ~]# yum -y install etcd [root@k8sbalanceetcd1 ~]# rpm -qa | grep etcdetcd-3.3.11-2.el7.centos.x86_64
修改etcd配置文件/etc/etcd/etcd.conf。
[root@k8sbalanceetcd1 ~]# ls /etc/etcd/etcd.conf[root@k8sbalanceetcd1 ~]# vim /etc/etcd/etcd.conf[root@k8sbalanceetcd1 ~]# cat /etc/etcd/etcd.conf#配置数据目录ETCD_DATA_DIR="/var/lib/etcd/cluster.etcd"ETCD_LISTEN_PEER_URLS="http://192.168.110.135:2380,http://localhost:2380"ETCD_LISTEN_CLIENT_URLS="http://192.168.110.135:2379,http://localhost:2379"ETCD_NAME="etcd135"ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.110.135:2380"ETCD_ADVERTISE_CLIENT_URLS="http://192.168.110.135:2379,http://localhost:2379"##目前是两个节点,所以这里是两个节点的etcdETCD_INITIAL_CLUSTER="etcd135=http://192.168.110.135:2380,etcd136=http://192.168.110.136:2380"##集群tokenETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"##新创建etcd集群的时候ETCD_INITIAL_CLUSTER_STATE="new",往已经存在的etcd集群添加etcd节点时:ETCD_INITIAL_CLUSTER_STATE="existing"ETCD_INITIAL_CLUSTER_STATE="new"
设置etcd开机自启动并现在就启动。
[root@k8sbalanceetcd1 ~]# systemctl enable etcd --now [root@k8sbalanceetcd1 ~]# systemctl status etcd● etcd.service - Etcd Server Loaded: loaded (/usr/lib/systemd/system/etcd.service; enabled; vendor preset: disabled) Active: active (running) since 六 2022-04-09 11:34:09 CST; 6h ago Main PID: 968 (etcd) CGroup: /system.slice/etcd.service └─968 /usr/bin/etcd --name=etcd135 --data-dir=/var/lib/etcd/cluster.etcd --listen-client-urls=http://192.168.110.135:2379,http://localhost:2379
另外一节点也安装etcd。
[root@k8sbalanceetcd2 ~]# yum -y install etcd
修改etcd配置文件。
[root@k8sbalanceetcd2 ~]# vim /etc/etcd/etcd.conf[root@k8sbalanceetcd2 ~]# ls /etc/etcd/etcd.conf[root@k8sbalanceetcd2 ~]# cat /etc/etcd/etcd.conf#配置数据目录ETCD_DATA_DIR="/var/lib/etcd/cluster.etcd"ETCD_LISTEN_PEER_URLS="http://192.168.110.136:2380,http://localhost:2380"ETCD_LISTEN_CLIENT_URLS="http://192.168.110.136:2379,http://localhost:2379"ETCD_NAME="etcd136"ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.110.136:2380"ETCD_ADVERTISE_CLIENT_URLS="http://192.168.110.136:2379,http://localhost:2379"##目前是两个节点,所以这里是两个节点的etcdETCD_INITIAL_CLUSTER="etcd135=http://192.168.110.135:2380,etcd136=http://192.168.110.136:2380"##集群tokenETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"##新创建etcd集群的时候ETCD_INITIAL_CLUSTER_STATE="new",往已经存在的etcd集群添加etcd节点时:ETCD_INITIAL_CLUSTER_STATE="existing"ETCD_INITIAL_CLUSTER_STATE="new"
设置etcd开机自启动,并现在就启动。
[root@k8sbalanceetcd2 ~]# systemctl enable etcd --now [root@k8sbalanceetcd2 ~]# systemctl status etcd
两个etcd节点都启动之后,查看etcd集群成员。
[root@k8sbalanceetcd1 ~]# etcdctl member list36adf18604130cea: name=etcd135 peerURLs=http://192.168.110.135:2380 clientURLs=http://192.168.110.135:2379,http://localhost:2379 isLeader=false 64d719893344455b: name=etcd136 peerURLs=http://192.168.110.136:2380 clientURLs=http://192.168.110.136:2379,http://localhost:2379 isLeader=true
查看集群健康状态。
[root@k8sbalanceetcd1 ~]# etcdctl cluster-healthmember 36adf18604130cea is healthy: got healthy result from http://192.168.110.135:2379 member 64d719893344455b is healthy: got healthy result from http://192.168.110.136:2379 cluster is healthy
查看/下的数据。
[root@k8sbalanceetcd1 ~]# etcdctl ls /
自此,做共享数据的etcd集群配置好了。
七.部署Kubernetes(k8s) master HA
本次Kubernetes(k8s)集群,有2个master节点,1个worker节点。
7.1 配置docker
k8s是容器编排工具,需要容器,所以三个节点同时安装docker。
[root@k8sbalancemaster1 ~]# yum -y install docker-ce
设置docker开机自启动并现在启动docker。
[root@k8sbalancemaster1 ~]# systemctl enable docker --now [root@k8sbalancemaster1 ~]# systemctl status docker
查看docker版本。
[root@k8sbalancemaster1 ~]# docker --versionDocker version 20.10.14, build a224086
配置docker镜像加速器。
[root@k8sbalancemaster1 ~]# cat /etc/docker/daemon.json{"registry-mirrors": ["https://frz7i079.mirror.aliyuncs.com"]}重启docker。
[root@k8sbalancemaster1 ~]# systemctl restart docker [root@k8sbalancemaster1 ~]# systemctl status docker
设置iptables不对bridge的数据进行处理,启用IP路由转发功能。
[root@k8sbalancemaster1 ~]# cat <<EOF> /etc/sysctl.d/k8s.conf > net.bridge.bridge-nf-call-ip6tables = 1 > net.bridge.bridge-nf-call-iptables = 1 > net.ipv4.ip_forward = 1 > EOF
使配置生效。
[root@k8sbalancemaster1 ~]# sysctl -p /etc/sysctl.d/k8s.confnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1net.ipv4.ip_forward = 1
7.2 安装kubelet,kubeadm,kubectl
查看可用的kubeadm版本。
[root@k8sbalancemaster1 ~]# yum list --showduplicates kubeadm --disableexcludes=kubernetes | grep 1.23kubeadm.x86_64 1.23.1-0 @kubernetes kubeadm.x86_64 1.23.0-0 kubernetes kubeadm.x86_64 1.23.1-0 kubernetes kubeadm.x86_64 1.23.2-0 kubernetes kubeadm.x86_64 1.23.3-0 kubernetes kubeadm.x86_64 1.23.4-0 kubernetes kubeadm.x86_64 1.23.5-0 kubernetes
此次k8s集群,我们安装k8s 1.23.1版本,三个节点都安装kubelet,kubeadm,kubectl,--disableexcludes=kubernetes 禁掉除了这个之外的别的仓库。
[root@k8sbalancemaster1 ~]# yum -y install kubelet-1.23.1-0 kubeadm-1.23.1-0 kubectl-1.23.1-0 --disableexcludes=kubernetes
设置kubelet开机自启动并现在就启动。
[root@k8sbalancemaster1 ~]# systemctl enable kubelet --now
注意:kubelet现在是启动不了的。
[root@k8sbalancemaster1 ~]# systemctl status kubelet
docker的cgroup driver需要修改为systemd,默认docker的cgroup driver是cgroupfs,k8s 1.23.1版本,如果不加"exec-opts": ["native.cgroupdriver=systemd"]参数,进行kubeadm init初始化的时候会报错如下:failed to run Kubelet: misconfiguration: kubelet cgroup driver: "systemd" is differ 根据报错信息知道,是因为 k8s 和docker 的 cgroup driver 不一致导致的,k8s 的是 systemd ,而 docker 是cgroupfs。
[root@k8sbalancemaster1 ~]# cat /etc/docker/daemon.json {"registry-mirrors": ["https://frz7i079.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"]}修改了/etc/docker/daemon.json之后,要重启docker进行生效。
[root@k8sbalancemaster1 ~]# systemctl restart docker
可以查看docker的 Cgroup Driver。
[root@k8sbalancemaster1 ~]# docker info | grep Cgroup Cgroup Driver: systemd Cgroup Version: 1
7.3 kubeadm初始化
在k8sbalancemaster1节点进行kubeadm init初始化,kubeadm初始化命令:kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.23.1 --pod-network-cidr=10.244.0.0/16,本次我们使用的是外部的etcd集群,而不是以容器运行的etcd,所以不能使用以上命令初始化k8s集群,kubeadm init --help 可以查看k8s集群初始化的各种命令。本次我们使用kubeadm config文件进行k8s初始化。
kubeadm config文件可以去存在的k8s集群上生成,没有的话直接按照模板改就行。
[root@k8scloude1 ~]# kubeadm config viewCommand "view" is deprecated, This command is deprecated and will be removed in a future release, please use 'kubectl get cm -o yaml -n kube-system kubeadm-config' to get the kubeadm config directly.apiServer:
extraArgs:
authorization-mode: Node,RBAC timeoutForControlPlane: 4m0sapiVersion: kubeadm.k8s.io/v1beta2certificatesDir: /etc/kubernetes/pkiclusterName: kubernetescontrollerManager: {}dns:
type: CoreDNSetcd:
local:
dataDir: /var/lib/etcdimageRepository: registry.aliyuncs.com/google_containerskind: ClusterConfigurationkubernetesVersion: v1.21.9networking:
dnsDomain: cluster.local podSubnet: 10.244.0.0/16 serviceSubnet: 10.96.0.0/12scheduler: {}生成kubeadm config文件。
[root@k8scloude1 ~]# kubeadm config view >kubeadm_config.yaml
把kubeadm config文件传到k8sbalancemaster1机器。
[root@k8scloude1 ~]# scp kubeadm_config.yaml 192.168.110.137:~/
修改kubeadm config文件:
controlPlaneEndpoint: "192.168.110.134:6443"指向haproxy的6443端口
http://192.168.110.135:2379 http://192.168.110.136:2379指向外部的etcd集群,数据是写入etcd集群的leader节点
kubernetesVersion: v1.23.1 指定k8s的版本
podSubnet: 10.244.0.0/16 指定pod网段地址
serviceSubnet: 10.96.0.0/12 指定服务网段地址
[root@k8sbalancemaster1 ~]# vim kubeadm_config.yaml[root@k8sbalancemaster1 ~]# cat kubeadm_config.yamlapiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
controlPlaneEndpoint: "192.168.110.134:6443"clusterName: kubernetes
controllerManager: {}dns:
type: CoreDNS
etcd:
external:
endpoints:
- "http://192.168.110.135:2379"
- "http://192.168.110.136:2379"imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.23.1
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}进行kubeadm初始化时,注意内存不应该少于1700M,不然会报错如下: #[ERROR Mem]: the system RAM (1346 MB) is less than the minimum 1700 MB 内存不应该小于1700 MB。
kubeadm初始化。
[root@k8sbalancemaster1 ~]# kubeadm init --config=kubeadm_config.yaml
进行kubeadm初始化的时候会去下载相应镜像,可以使用 docker images查看镜像下载情况。
[root@k8sbalancemaster1 ~]# docker images
kubeadm初始化成功之后,按照提示拷贝kubeconfig文件并授权。
[root@k8sbalancemaster1 ~]# mkdir -p $HOME/.kube [root@k8sbalancemaster1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@k8sbalancemaster1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
7.4 添加master/worker节点到k8s集群
如果一个k8s集群有多个master,则以控制面的方式加入k8s集群,命令为:kubeadm join 192.168.110.134:6443 --token 3pc2kl.36wdzgtwutm9fll0 --discovery-token-ca-cert-hash sha256:0b311caadf2439b261849f50edadda3926c42f15b6f8cf6489f0dfec6393cf0b --control-plane
worker节点加入k8s集群则使用命令:kubeadm join 192.168.110.134:6443 --token 3pc2kl.36wdzgtwutm9fll0 --discovery-token-ca-cert-hash sha256:0b311caadf2439b261849f50edadda3926c42f15b6f8cf6489f0dfec6393cf0b
下面把k8sbalanceworker1加入集群。
[root@k8sbalanceworker1 ~]# kubeadm join 192.168.110.134:6443 --token 3pc2kl.36wdzgtwutm9fll0 --discovery-token-ca-cert-hash sha256:0b311caadf2439b261849f50edadda3926c42f15b6f8cf6489f0dfec6393cf0b
k8sbalanceworker1加入集群之后,可以看到k8sbalanceworker1加入了集群,但是STATUS为NotReady,等我们安装了calico网络插件之后,STATUS会变为Ready的。
[root@k8sbalancemaster1 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 NotReady control-plane,master 3d9h v1.23.1 k8sbalanceworker1 NotReady <none> 3d9h v1.23.1
把k8sbalancemaster2以控制面的方式加入k8s集群,作为第二个k8s master节点,执行如下命令会报错,原因是没有各种证书。
如果我们把k8sbalancemaster1下/etc/kubernetes/pki的所有证书都拷贝过来,k8sbalancemaster2加入集群的时候还是会报错。
[root@k8sbalancemaster2 ~]# kubeadm join 192.168.110.134:6443 --token 3pc2kl.36wdzgtwutm9fll0 --discovery-token-ca-cert-hash sha256:0b311caadf2439b261849f50edadda3926c42f15b6f8cf6489f0dfec6393cf0b --control-plane
kubeadm reset清空设置。
[root@k8sbalancemaster2 ~]# kubeadm reset
把k8sbalancemaster1目录/etc/kubernetes/pki/下的ca.crt , ca.key ,sa.key ,sa.pub ,front-proxy-ca.key ,front-proxy-ca.crt 文件拷贝到k8sbalancemaster2目录/etc/kubernetes/pki下,再次把k8sbalancemaster2以控制面的方式加入k8s集群,这次k8sbalancemaster2就加入k8s集群成功了。
[root@k8sbalancemaster2 ~]# kubeadm join 192.168.110.134:6443 --token 3pc2kl.36wdzgtwutm9fll0 --discovery-token-ca-cert-hash sha256:0b311caadf2439b261849f50edadda3926c42f15b6f8cf6489f0dfec6393cf0b --control-plane
按照提示拷贝kubeconfig文件并授权。
[root@k8sbalancemaster2 ~]# mkdir -p $HOME/.kube [root@k8sbalancemaster2 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@k8sbalancemaster2 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
k8sbalancemaster2加入集群之后,可以发现此时三个节点的状态都是NotReady的,是因为没有CNI网络插件,为了节点间的通信,需要安装cni网络插件,需要去官网下载calico.yaml文件。
[root@k8sbalancemaster1 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 NotReady control-plane,master 3d10h v1.23.1 k8sbalancemaster2 NotReady control-plane,master 3d9h v1.23.1 k8sbalanceworker1 NotReady <none> 3d10h v1.23.1
7.5 部署CNI网络插件calico
虽然现在k8s集群已经有2个master节点,1个worker节点,但是此时三个节点的状态都是NotReady的,原因是没有CNI网络插件,为了节点间的通信,需要安装cni网络插件,常用的cni网络插件有calico和flannel,两者区别为:flannel不支持复杂的网络策略,calico支持网络策略,因为今后还要配置k8s网络策略networkpolicy,所以本文选用的cni网络插件为calico!
创建放calico文件的目录。
[root@k8sbalancemaster1 ~]# mkdir cni [root@k8sbalancemaster1 ~]# cd cni/
下载calico部署文件。
[root@k8sbalancemaster1 cni]# curl https://docs.projectcalico.org/manifests/calico.yaml -O [root@k8sbalancemaster1 cni]# lscalico.yaml
查看需要下载的calico镜像,这四个镜像需要在所有节点都下载。
[root@k8sbalancemaster1 cni]# grep image calico.yaml image: docker.io/calico/cni:v3.22.1 image: docker.io/calico/cni:v3.22.1 image: docker.io/calico/pod2daemon-flexvol:v3.22.1 image: docker.io/calico/node:v3.22.1 image: docker.io/calico/kube-controllers:v3.22.1
拉取镜像。
[root@k8sbalancemaster1 cni]# docker pull docker.io/calico/cni:v3.22.1 [root@k8sbalancemaster1 cni]# docker pull docker.io/calico/node:v3.22.1 [root@k8sbalancemaster1 cni]# docker pull docker.io/calico/kube-controllers:v3.22.1 [root@k8sbalancemaster1 cni]# docker pull docker.io/calico/pod2daemon-flexvol:v3.22.1 [root@k8sbalancemaster1 cni]# docker images | grep calicocalico/kube-controllers v3.22.1 c0c6672a66a5 5 weeks ago 132MB calico/cni v3.22.1 2a8ef6985a3e 5 weeks ago 236MB calico/pod2daemon-flexvol v3.22.1 17300d20daf9 5 weeks ago 19.7MB calico/node v3.22.1 7a71aca7b60f 5 weeks ago 198MB#下载calico镜像[root@k8sbalancemaster2 ~]# docker pull docker.io/calico/cni:v3.22.1 [root@k8sbalancemaster2 ~]# docker pull docker.io/calico/node:v3.22.1 [root@k8sbalancemaster2 ~]# docker pull docker.io/calico/kube-controllers:v3.22.1 [root@k8sbalancemaster2 ~]# docker pull docker.io/calico/pod2daemon-flexvol:v3.22.1 [root@k8sbalancemaster2 ~]# docker images | grep calicocalico/kube-controllers v3.22.1 c0c6672a66a5 5 weeks ago 132MB calico/cni v3.22.1 2a8ef6985a3e 5 weeks ago 236MB calico/pod2daemon-flexvol v3.22.1 17300d20daf9 5 weeks ago 19.7MB calico/node v3.22.1 7a71aca7b60f 5 weeks ago 198MB#下载calico镜像[root@k8sbalanceworker1 ~]# docker pull docker.io/calico/cni:v3.22.1 [root@k8sbalanceworker1 ~]# docker pull docker.io/calico/node:v3.22.1 [root@k8sbalanceworker1 ~]# docker pull docker.io/calico/kube-controllers:v3.22.1 [root@k8sbalanceworker1 ~]# docker pull docker.io/calico/pod2daemon-flexvol:v3.22.1 [root@k8sbalanceworker1 ~]# docker images | grep calicocalico/kube-controllers v3.22.1 c0c6672a66a5 5 weeks ago 132MB calico/cni v3.22.1 2a8ef6985a3e 5 weeks ago 236MB calico/pod2daemon-flexvol v3.22.1 17300d20daf9 5 weeks ago 19.7MB calico/node v3.22.1 7a71aca7b60f 5 weeks ago 198MB
安装calico。
[root@k8sbalancemaster1 cni]# kubectl apply -f calico.yaml
查看ds。
[root@k8sbalancemaster1 cni]# kubectl get dsNo resources found in default namespace.[root@k8sbalancemaster1 cni]# kubectl get ds -ANAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-system calico-node 3 3 3 3 3 kubernetes.io/os=linux 3d9h kube-system kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 3d10h
7.6 配置kubectl命令tab键自动补全
查看kubectl自动补全命令。
[root@k8sbalancemaster1 cni]# kubectl --help | grep bash completion Output shell completion code for the specified shell (bash, zsh or fish)
添加source <(kubectl completion bash)到/etc/profile,并使配置生效。
[root@k8sbalancemaster1 cni]# vim /etc/profile [root@k8sbalancemaster1 cni]# grep completion /etc/profilesource <(kubectl completion bash)[root@k8sbalancemaster1 cni]# source /etc/profile
此时即可kubectl命令tab键自动补全,可以看到所有k8s节点都是Ready状态。
[root@k8sbalancemaster1 cni]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d12h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d11h v1.23.1 k8sbalanceworker1 Ready <none> 3d12h v1.23.1
八.测试k8s的两个master节点数据是否能同步
查看namespace。
[root@k8sbalancemaster1 cni]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h
创建masterha命名空间。
[root@k8sbalancemaster1 cni]# kubectl create ns masterhanamespace/masterha created
在master1节点创建命名空间masterha,在master2上也可以看到该命名空间。
[root@k8sbalancemaster2 ~]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h masterha Active 17s
在master2创建命名空间master2。
[root@k8sbalancemaster2 ~]# kubectl create ns master2namespace/master2 created
在master2节点创建命名空间master2,在master1上也可以看到该命名空间。
[root@k8sbalancemaster1 cni]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h master2 Active 20s masterha Active 51s
下面测试k8s的两个master,其中一个master宕机,k8s集群是否能正常工作。
把k8sbalancemaster1节点关机。
[root@k8sbalancemaster1 cni]# init 0
把k8sbalancemaster1节点关机之后,k8sbalancemaster2也可以正常查看节点状态。
[root@k8sbalancemaster2 ~]# kubectl get nodeUnable to connect to the server: net/http: TLS handshake timeout[root@k8sbalancemaster2 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 NotReady control-plane,master 3d12h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d11h v1.23.1 k8sbalanceworker1 Ready <none> 3d12h v1.23.1
k8sbalancemaster2也可以创建命名空间和查看命名空间。
[root@k8sbalancemaster2 ~]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h master2 Active 4m16s masterha Active 4m47s[root@k8sbalancemaster2 ~]# kubectl create ns yoyonamespace/yoyo created[root@k8sbalancemaster2 ~]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h master2 Active 5m58s masterha Active 6m29s yoyo Active 3s
现在启动k8sbalancemaster1。
可以发现,k8s的一个master节点关闭之后,只要另外一个master还在运行,集群就还可以正常运行,并且k8sbalancemaster1关闭期间,在k8sbalancemaster2创建的数据,等k8sbalancemaster1恢复之后会自动同步数据。
[root@k8sbalancemaster1 ~]# kubectl get nsNAME STATUS AGE default Active 3d12h kube-node-lease Active 3d12h kube-public Active 3d12h kube-system Active 3d12h master2 Active 8m23s masterha Active 8m54s yoyo Active 2m28s
现在整个集群都是正常的了。
[root@k8sbalancemaster1 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d12h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d11h v1.23.1 k8sbalanceworker1 Ready <none> 3d12h v1.23.1
九.使用客户端访问k8s集群
接下来使用客户端访问k8s集群,把etcd2机器作为k8s的客户端。
在k8sbalancemaster1查看kubectl文件位置。
[root@k8sbalancemaster1 ~]# which kubectl/usr/bin/kubectl
把kubectl文件拷贝到客户端,或者客户端直接下载kubectl文件也可以。
[root@k8sbalancemaster1 ~]# scp /usr/bin/kubectl 192.168.110.131:~/
从k8s集群拷贝一个kubectl文件或者下载一个kubectl文件。
[root@etcd2 ~]# mv kubectl /usr/bin/ [root@etcd2 ~]# which kubectl/usr/bin/kubectl
现在客户端是访问不了k8s集群的。
[root@etcd2 ~]# kubectl get nodeThe connection to the server localhost:8080 was refused - did you specify the right host or port?
客户端访问k8s集群可以使用kubeconfig文件的方式,也可以通过token的方式,关于身份认证的详细内容,请查看博客《Kubernetes(k8s)访问控制:身份认证》。
本次使用kubeconfig文件访问k8s集群,先在k8sbalancemaster1节点创建一个kubeconfig文件。
创建存放kubeconfig文件的目录。
[root@k8sbalancemaster1 ~]# mkdir ca [root@k8sbalancemaster1 ~]# cd ca[root@k8sbalancemaster1 ca]# pwd/root/ca
下面开始申请证书,创建私钥,名字可以自己命名为haproxy.key,因为我们是通过haproxy负载均衡,把请求转发给两个k8s的master节点的,所以我们创建haproxy用户。
[root@k8sbalancemaster1 ca]# openssl genrsa -out haproxy.key 2048
利用刚生成的私钥haproxy.key 生成证书请求文件 haproxy.csr,CN 的值为haproxy,就是我们授权的用户。
[root@k8sbalancemaster1 ca]# openssl req -new -key haproxy.key -out haproxy.csr -subj "/CN=haproxy/O=cloude2022"
对证书请求文件haproxy.csr进行 base64 编码。
[root@k8sbalancemaster1 ca]# cat haproxy.csr | base64 | tr -d "\n"
编写申请证书请求文件的 yaml 文件,注意:对于k8s V1.21.1版本,我们使用的api版本为:apiVersion: certificates.k8s.io/v1beta1 ,并且注释掉signerName: kubernetes.io/legacy-aa,但是对于k8s v1.23.1版本,api版本为apiVersion: certificates.k8s.io/v1,并且需要signerName,经过测试,signerName: kubernetes.io/kube-apiserver-client能正确生成证书请求文件,另外两种signerName都有问题,注意这里 apiVersion 要带 beta1,否则 signerName 那行就不能注释掉,但这样的话后面的 操作就不能获取到证书。这里 request 里的是 base64 编码之后的证书请求文件。
[root@k8sbalancemaster1 ca]# vim csr.yaml[root@k8sbalancemaster1 ca]# cat csr.yaml#apiVersion: certificates.k8s.io/v1beta1apiVersion: certificates.k8s.io/v1 kind: CertificateSigningRequest metadata: name: haproxy spec: groups: - system:authenticated #signerName: kubernetes.io/legacy-aa request: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0KTUlJQ2JEQ0NBVlFDQVFBd0p6RVFNQTRHQTFVRUF3d0hhR0Z3Y205NGVURVRNQkVHQTFVRUNnd0tZMnh2ZFdSbApNakF5TWpDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTTNMbXkyRnN3azZweFRWCmZ5SmhnUEVLSnZvcHN4bnVERGF5UStFSlFaWlk0SjA5cXlndXVvaXRxTTZ5YTRUcEV1Uy9wWldEajJOTjYwOTIKWmhCcUxTMzhsMGlQWE5lbzRLRlVQUEVQc2ZKeEgrclNGOUg1bE44VjlQSnJHZ1pDdFJITC8rUlNTc1N2ZkJMZgpmdThZL0N3czUvNXdMVXkyL1gySW5GWGUyTVlTNjZmWHBOY1VaUmxnUEVkZTJoK1BHemwrWEwrYzN3c080aEduCjlXYmRhS2R4YVJvaW9zc1VaRFlxcnQwOGFsdjNHdDJSYkRFUDhTLzExMWFTbEQ0blZKTHhZdUM5VXdib3RTdTMKeXN5RzVHUmZmMmpMMlBJaENoMFd0ZUl1clRQY2JTSSt2bklPb29XdjBQeDdzRzlnMFpVWW54RFpHdzU4Q3JhTApieUZlVHdNQ0F3RUFBYUFBTUEwR0NTcUdTSWIzRFFFQkN3VUFBNElCQVFDSXJpelJXVzB2K1FadlZ4NG5VR2pnCjFGaXdaOWg3YW1sdzdQUDUrcFRFNG40MGh3Y1B4Z3k3cDhoaG9VY2VsRWtxM0ZLMm5tTjFtaGdVbFJrWHdVQS8KWWtNd3BXWTE1TE82Zmtod1YrODQ0MVRkN01mTWFPR25SNHAzV1NId3dtQWJyb0dVVm54NFZWcEpFYi9SQTZ4TQpLc3FjTDJpbG5IK2xPZkNEODhnSndwWGxjQ3BxbnEvRTFUUmt0WUZuKzZPSWZzRGsvVWRxN0tPRFBvakN5ZFlZClNsL2lFS094TlQwam1MSWRpZ0RGSXNRa2RxUXRGZnNCMjF5K1krNVJDeGZabGVkRTRIb0VHNnJSZTNtR01peDMKMm1pNG9TTm00MzhacEUrNjliOCtFN3pzbUNZcHNMWnBzSEhUdzlLVzBENUFOY3dWSGVTbk9rZWV4djRoK0hWbQotLS0tLUVORCBDRVJUSUZJQ0FURSBSRVFVRVNULS0tLS0K #signerName: kubernetes.io/kubelet-serving signerName: kubernetes.io/kube-apiserver-client usages: - client auth
申请证书。
[root@k8sbalancemaster1 ca]# kubectl apply -f csr.yaml
查看已经发出证书申请的请求。
[root@k8sbalancemaster1 ca]# kubectl get csr -o wide
批准证书。
[root@k8sbalancemaster1 ca]# kubectl certificate approve haproxy
查看审批通过的证书。
[root@k8sbalancemaster1 ca]# kubectl get csr -o wide[root@k8sbalancemaster1 ca]# kubectl get csr haproxy -o yaml
只查看certificate字段。
[root@k8sbalancemaster1 ca]# kubectl get csr/haproxy -o jsonpath='{.status.certificate}'对certificate解码并导出证书文件。
[root@k8sbalancemaster1 ca]# kubectl get csr/haproxy -o jsonpath='{.status.certificate}' | base64 -d > haproxy.crt [root@k8sbalancemaster1 ca]# cat haproxy.crt-----BEGIN CERTIFICATE-----
MIIDDTCCAfWgAwIBAgIRAMtBJdW9NhxGrZeQ6kxQ7powDQYJKoZIhvcNAQELBQAw
FTETMBEGA1UEAxMKa3ViZXJuZXRlczAeFw0yMjA0MDgwOTE5NTFaFw0yMzA0MDgw
OTE5NTFaMCcxEzARBgNVBAoTCmNsb3VkZTIwMjIxEDAOBgNVBAMTB2hhcHJveHkw
ggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQDNy5sthbMJOqcU1X8iYYDx
Cib6KbMZ7gw2skPhCUGWWOCdPasoLrqIrajOsmuE6RLkv6WVg49jTetPdmYQai0t
/JdIj1zXqOChVDzxD7HycR/q0hfR+ZTfFfTyaxoGQrURy//kUkrEr3wS337vGPws
LOf+cC1Mtv19iJxV3tjGEuun16TXFGUZYDxHXtofjxs5fly/nN8LDuIRp/Vm3Win
cWkaIqLLFGQ2Kq7dPGpb9xrdkWwxD/Ev9ddWkpQ+J1SS8WLgvVMG6LUrt8rMhuRk
X39oy9jyIQodFrXiLq0z3G0iPr5yDqKFr9D8e7BvYNGVGJ8Q2RsOfAq2i28hXk8D
AgMBAAGjRjBEMBMGA1UdJQQMMAoGCCsGAQUFBwMCMAwGA1UdEwEB/wQCMAAwHwYD
VR0jBBgwFoAUk+IKVztCgmAPMQOPURy9OqPMy9owDQYJKoZIhvcNAQELBQADggEB
ACwohGXvBvQ4Yrx+Vdt7Q5IUInqa2XHHZ5XWlyqFVctR4IJ/PJz/B7DnWIFiwSJQ
GZDtBvM63+u23zED8EMveggTkB23P6y8/Wqznt8zsGGARYLp73oCqWIQcWpnrrnA
whGYOK6x6iRpHrHWrrfn+wIr/vQIG2glj7FxRJpAmISLtqdLihRIQ2vITRdRqYXn
wnJIKCtVyK5T78pnZRJEC4pQsfcX+xNH/sA8HVY04YnhzqtyDyuuA0IxMmBV34bL
34AWyiYzo7QvVKC7LkMVpIfZ2V7755RLm6oPTgPD5P6/uCRpI3pRlg83mRuRH0W7
dV0DcIQ/63k8cR/ovU9Qbrc=-----END CERTIFICATE-----拷贝 CA 证书到当前目录。
[root@k8sbalancemaster1 ca]# cp /etc/kubernetes/pki/ca.crt .
kubeconfig文件包含3个字段:cluster,user,context上下文(可以把cluster和user关联在一起)。
kubeconfig文件里,clusters 字段指定 kubernetes 集群的信息,users 指定用户,contexts 用于 指定上下文包括用户默认所在的命名空间等信息。
设置集群字段:
--kubeconfig指定生成的kubeconfig文件名,
set-cluster指定集群名,
--server指定连接到哪个k8s上,--server设置连接到哪一个k8s master节点上,我们可以连接master1或者master2,haproxy是我们的负载均衡器,我们连接haproxy的6443端口,haproxy会把请求转发给后端的两个master节点,所以我们--server=https://192.168.110.134:6443连接的是haproxy端口。
--certificate-authority 指定CA证书,
--embed-certs=true 的意思是把CA证书内 容写入到此 kubeconfig >文件里。
[root@k8sbalancemaster1 ca]# kubectl config --kubeconfig=haproxykubeconfig set-cluster clusterhaproxy --server=https://192.168.110.134:6443 --certificate-authority=ca.crt --embed-certs=true
设置用户字段。
[root@k8sbalancemaster1 ca]# kubectl config --kubeconfig=haproxykubeconfig set-credentials haproxy --client-certificate=haproxy.crt --client-key=haproxy.key --embed-certs=true
设置上下文字段。
[root@k8sbalancemaster1 ca]# kubectl config --kubeconfig=haproxykubeconfig set-context contexthaproxy --cluster=clusterhaproxy --namespace=default --user=haproxy
修改haproxykubeconfig文件,把当前上下文修改为current-context: "contexthaproxy"。
[root@k8sbalancemaster1 ca]# vim haproxykubeconfig[root@k8sbalancemaster1 ca]# cat haproxykubeconfigapiVersion: v1clusters:- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1EUXdOekUzTWprd05Wb1hEVE15TURRd05ERTNNamt3TlZvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTktJCkFUTk8wd2ZFR2ZVR1UxcG1URUtFMy9Jbk9GRkdkSXQ4S1BON2Q3a0RvbFlvbmN2TjRIYWttRmJ0T2FmY2lUakoKNnNFRG81VExXbFd4elZ6MThuWVJoYW45TWplUXNROGk3cHIxTnp4S3ZpbXNMSE9VTEt6VzhjL1JlbmJnRDNoTQpVU2JwbUo4UGhBMXhGZEpIOEJaclh4QTVQRFo4cjQ4TGZReVREZFFQSmh5OE9qN1JsOXkwS3BlbUlHOXhBanNBCkliQWlITFZIZXRaMmRRSStJYnZRbDB5L1dybVc0WFFNeWJ0VXFYUTFWT3F5a2VGeUdyelR3aFhVYTVJanQ1cnYKVFNOV3RDM21FQXJ2Nmk5VDlOY3VKcXdiVWgxZUJsT0Vkc0hYdm4yOCtVRzJFeFdTV3AxY0dYbDd0bkhkT1kwZAp4OFQ1NEVrQXlJM0lLR3l3Sy9NQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZKUGlDbGM3UW9KZ0R6RURqMUVjdlRxanpNdmFNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBSHV0em82WEFkSjBUbU8zRFFxRgp6bkVHOGNuQW5IbjRWZVZ6dWNrcVV0aEV5d3J6ekF0U0dhazlZM2tlVjlkSXhGN1pwUHc4bHN3T3FPbGJOQldTCjMxaHhja3hac3V6MTBOZmduTnlLa3UwV2pyVmxuOU5EZjhEcWRuR0psRXVHQ25ZTCtiMFJzcE9tdFNJQXZZVlAKckdleTAwK3U4NmsyMVE3dUlqK1oyWkhJUDJiUysxNGQrUTJSeVFuYnVkV1JERm4zK0twL2p1ZGJqRHVvRXZKNgpxVkl6ZU9kY0VYQ2ZEanVrdkY4VXlBVUQrTm9BSTNqbWdSbVZMMDRTUGRReUpPcnRUZ1hmYW9xYTBxVVI1Z1V3CjEvUmtMc295Q21UMVhMY3FnYllQSU1VcWpWanRidDFSTXpsQ3lUUkJWRU1UYlJYa1NVcklLUlZwaEU2ZTRXc1AKaFJjPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg== server: https://192.168.110.134:6443
name: clusterhaproxycontexts:- context:
cluster: clusterhaproxy namespace: default user: haproxy name: contexthaproxycurrent-context: "contexthaproxy"kind: Configpreferences: {}users:- name: haproxy user:
client-certificate-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREVENDQWZXZ0F3SUJBZ0lSQU10QkpkVzlOaHhHclplUTZreFE3cG93RFFZSktvWklodmNOQVFFTEJRQXcKRlRFVE1CRUdBMVVFQXhNS2EzVmlaWEp1WlhSbGN6QWVGdzB5TWpBME1EZ3dPVEU1TlRGYUZ3MHlNekEwTURndwpPVEU1TlRGYU1DY3hFekFSQmdOVkJBb1RDbU5zYjNWa1pUSXdNakl4RURBT0JnTlZCQU1UQjJoaGNISnZlSGt3CmdnRWlNQTBHQ1NxR1NJYjNEUUVCQVFVQUE0SUJEd0F3Z2dFS0FvSUJBUUROeTVzdGhiTUpPcWNVMVg4aVlZRHgKQ2liNktiTVo3Z3cyc2tQaENVR1dXT0NkUGFzb0xycUlyYWpPc211RTZSTGt2NldWZzQ5alRldFBkbVlRYWkwdAovSmRJajF6WHFPQ2hWRHp4RDdIeWNSL3EwaGZSK1pUZkZmVHlheG9HUXJVUnkvL2tVa3JFcjN3UzMzN3ZHUHdzCkxPZitjQzFNdHYxOWlKeFYzdGpHRXV1bjE2VFhGR1VaWUR4SFh0b2ZqeHM1Zmx5L25OOExEdUlScC9WbTNXaW4KY1drYUlxTExGR1EyS3E3ZFBHcGI5eHJka1d3eEQvRXY5ZGRXa3BRK0oxU1M4V0xndlZNRzZMVXJ0OHJNaHVSawpYMzlveTlqeUlRb2RGclhpTHEwejNHMGlQcjV5RHFLRnI5RDhlN0J2WU5HVkdKOFEyUnNPZkFxMmkyOGhYazhECkFnTUJBQUdqUmpCRU1CTUdBMVVkSlFRTU1Bb0dDQ3NHQVFVRkJ3TUNNQXdHQTFVZEV3RUIvd1FDTUFBd0h3WUQKVlIwakJCZ3dGb0FVaytJS1Z6dENnbUFQTVFPUFVSeTlPcVBNeTlvd0RRWUpLb1pJaHZjTkFRRUxCUUFEZ2dFQgpBQ3dvaEdYdkJ2UTRZcngrVmR0N1E1SVVJbnFhMlhISFo1WFdseXFGVmN0UjRJSi9QSnovQjdEbldJRml3U0pRCkdaRHRCdk02Myt1MjN6RUQ4RU12ZWdnVGtCMjNQNnk4L1dxem50OHpzR0dBUllMcDczb0NxV0lRY1dwbnJybkEKd2hHWU9LNng2aVJwSHJIV3JyZm4rd0lyL3ZRSUcyZ2xqN0Z4UkpwQW1JU0x0cWRMaWhSSVEydklUUmRScVlYbgp3bkpJS0N0VnlLNVQ3OHBuWlJKRUM0cFFzZmNYK3hOSC9zQThIVlkwNFluaHpxdHlEeXV1QTBJeE1tQlYzNGJMCjM0QVd5aVl6bzdRdlZLQzdMa01WcElmWjJWNzc1NVJMbTZvUFRnUEQ1UDYvdUNScEkzcFJsZzgzbVJ1UkgwVzcKZFYwRGNJUS82M2s4Y1Ivb3ZVOVFicmM9Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K client-key-data: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcFFJQkFBS0NBUUVBemN1YkxZV3pDVHFuRk5WL0ltR0E4UW9tK2ltekdlNE1OckpENFFsQmxsamduVDJyCktDNjZpSzJvenJKcmhPa1M1TCtsbFlPUFkwM3JUM1ptRUdvdExmeVhTSTljMTZqZ29WUTg4USt4OG5FZjZ0SVgKMGZtVTN4WDA4bXNhQmtLMUVjdi81RkpLeEs5OEV0OSs3eGo4TEN6bi9uQXRUTGI5ZllpY1ZkN1l4aExycDllawoxeFJsR1dBOFIxN2FINDhiT1g1Y3Y1emZDdzdpRWFmMVp0MW9wM0ZwR2lLaXl4UmtOaXF1M1R4cVcvY2EzWkZzCk1RL3hML1hYVnBLVVBpZFVrdkZpNEwxVEJ1aTFLN2ZLeklia1pGOS9hTXZZOGlFS0hSYTE0aTZ0TTl4dElqNisKY2c2aWhhL1EvSHV3YjJEUmxSaWZFTmtiRG53S3RvdHZJVjVQQXdJREFRQUJBb0lCQVFDWDdldlhGTENUYkxDegpDZGI5Qzl6RWxza2x3S2xQeUZWT0FCZHF5SW1hTkcxR3lLTldYQUVzTElER2NDUStrRTk1Zng4QW5ZcTdObWcxClZ1U00wOFlkQURDenlkc3gvNlF1bG1FVFdwSDF1Wnhsb01zaklrM00wSW53ZWk5UlZlZ1ZoblNaSEVQRXB3VkQKYmFwcFhCbTNoME9TclVCVU5YZzVPQ1NxcElXRzNGYm04dGZZcGlMV2d6a08zRU1mYWlxZHZSaVBlbTM2WjNIYwpjdWx5RXpCMjZXdXZadzFKRjgwdVBaVE5PcVJ2VnpmZWlzdFhPa0xhdEpXM3ZJbFFUaGE5eG9LL3orZmduazVmCittanFzWUluNU5HVDJmNXNPcEV5U1BQRDZOaGxFc3RzU2g3QTFZendTVGZKNm8xUkR1aFR5cXk2U1pON0NkWEYKbmR3K2tGRFJBb0dCQVBuOWFQcWRDdEVVMGlPZ1FkL1FGQVoyaEkxMXVGQWdNU2ZEUUMrMVBnSGV0SWZMeGZqYQpOZFMyVXdnRW5mazRrNTdwQUdYOHZCVTlLTmZuZXdXQjBUZHY3UkdDUmhOUkdEVWdybVppZmIvS3duU0xSMmxQCmlvSWlWTmpjdy8vdE4vRlljSVFzNXAreG9SVlpwNTZiQlNOd1lhQ2UybXR5T0wydUxtZ2F5Nzc1QW9HQkFOSysKTWltQjFTZ1RXL25RMDU4eG95cWFsY0RQSWpxbGtPKzRlNXFaQ0Evclc3SHVMblZMSlZxdGp4TER4bDE4dEZlRworK2ZHYkRLbmMvWkRRNjROL0pxUmxDTmR5UHQ3MnNmbEd4ZHhuWm9UbUUzdE4rU3pLT3NPY2RuU0hib0FZdGJmCjJISE05ak9pYTdmMm15bVlEelNxa3lERTJpUTMwSkJvUndHdDdYRGJBb0dCQUxDeXlLZ1RwcGlnZ2VRQ20yMUsKVTAwNktua2VremUzZVdja29GTFlaY3JHa281Rm4xcEZTclZlWmhRTngyZG44UmZxazRpQytxSjhoMGtNYWkwNwpWQmsrT0xBZWg4K1JpMjNKK3R1TmxGcWpRNDFEQVNmVHZCQTltZ0ZyRWZMc3hwVUZzUW9ML3JzenY2c3Fvc3I5CndjVUo0MGUzNEtUL3FGR1NNMlVNUTZWcEFvR0JBS2dwV28raWFUdWtUd1ZGckVmZ2JPbkhGbTRYR3FJZmtVcW8KTkFGRjBaZ2FYejNZNkR0eUxpbHdTclZYZ1FjQ1JrbDlqYThCdHo2b1BqRW90VzNDL1drOWR5N05YRjNJRStqawpHVDBZelFDd1dCeitpRlkyM0JUTW51Nkg2bTZNZGxJdHBtSVFnZmpyeHZheGtsaWJYSzdTMmJvUk9sd2lLWXZCCm1iOXVVUVIzQW9HQWRUNFRwdWxJWjVSTGxYYWJEc2h6NStBa21SR0gwL2tzNmF2WjdHbGRYL2lMb3R0NUJ2disKN3VsUEVPY2VYZnRuUjFrOWtvVVoyeGJTRVBzTmFqQ3BWaktnYkNPQy9VY2E5MmVhM3B3aFFRTk85RnZoQVhReApwck1yc2RLTEZGN3dwcHViT0FadXhId2NlaDk0YlkzRGJoNGl4eGthbzNQQjJwbU0zdG96dFVRPQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=此时haproxy用户的kubeconfig文件haproxykubeconfig就创建好了,客户端使用该文件就可以通过认证了。
[root@k8sbalancemaster1 ca]# lsca.crt csr.yaml haproxy.crt haproxy.csr haproxy.key haproxykubeconfig
把kubeconfig文件拷贝到客户端etcd2。
[root@k8sbalancemaster1 ca]# scp haproxykubeconfig 192.168.110.131:~/
etcd2机器收到kubeconfig文件了。
[root@etcd2 ~]# ll -h haproxykubeconfig-rw------- 1 root root 5.5K 4月 8 17:49 haproxykubeconfig
查看节点状态,可以看到haproxy用户认证通过了,只是没有权限,我们对用户haproxy进行授权即可访问k8s资源了。
[root@etcd2 ~]# kubectl get node --kubeconfig=haproxykubeconfigError from server (Forbidden): nodes is forbidden: User "haproxy" cannot list resource "nodes" in API group "" at the cluster scope
我们对用户haproxy进行授权,授权的详细内容,请查看博客《Kubernetes(k8s)访问控制:权限管理之RBAC鉴权》。
对haproxy用户授予cluster-admin的权限。
[root@k8sbalancemaster1 ca]# kubectl create clusterrolebinding haproxy --clusterrole=cluster-admin --user=haproxy clusterrolebinding.rbac.authorization.k8s.io/haproxy created
cluster-admin角色权限很大的,使用时请注意安全。
[root@k8sbalancemaster1 ca]# kubectl get clusterrolebinding | grep haproxyhaproxy ClusterRole/cluster-admin 9s
对用户haproxy进行授权之后,客户端etcd2可以查看k8s集群节点状态了。
[root@etcd2 ~]# kubectl get node --kubeconfig=haproxykubeconfigNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d13h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d12h v1.23.1 k8sbalanceworker1 Ready <none> 3d13h v1.23.1
也可以使用环境变量的方式。
[root@etcd2 ~]# export KUBECONFIG=haproxykubeconfig[root@etcd2 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d13h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d12h v1.23.1 k8sbalanceworker1 Ready <none> 3d13h v1.23.1
查看命名空间。
[root@etcd2 ~]# kubectl get nsNAME STATUS AGE default Active 3d13h kube-node-lease Active 3d13h kube-public Active 3d13h kube-system Active 3d13h master2 Active 53m masterha Active 53m yoyo Active 47m
十.测试Kubernetes(k8s)集群高可用
haproxykubeconfig文件中,server: https://192.168.110.134:6443表示连接的是haproxy端口,haproxy是我们的负载均衡器,当客户端连接haproxy: https://192.168.110.134:6443的时候,haproxy会把客户端请求转发给后端的两个master节点,当我们其中一个k8s的master节点宕机,也不影响Kubernetes(k8s)集群功能,这就是高可用。
现在把k8sbalancemaster2关机。
[root@k8sbalancemaster2 ~]# init 0
k8sbalancemaster2关机之后,在客户端etcd2查看命名空间。
[root@etcd2 ~]# kubectl get nsUnable to connect to the server: net/http: TLS handshake timeout[root@etcd2 ~]# kubectl get nsNAME STATUS AGE default Active 3d13h kube-node-lease Active 3d13h kube-public Active 3d13h kube-system Active 3d13h master2 Active 55m masterha Active 56m yoyo Active 49m
查看节点状态。
[root@etcd2 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d13h v1.23.1 k8sbalancemaster2 NotReady control-plane,master 3d12h v1.23.1 k8sbalanceworker1 Ready <none> 3d13h v1.23.1
可以发现就算k8sbalancemaster2节点宕机,客户端依旧可以正常访问k8s集群,并且不需要手动切换连接到另外一个正常的k8s master节点。
启动k8sbalancemaster2之后,所有节点都是Ready状态。
[root@etcd2 ~]# kubectl get nodeNAME STATUS ROLES AGE VERSION k8sbalancemaster1 Ready control-plane,master 3d13h v1.23.1 k8sbalancemaster2 Ready control-plane,master 3d12h v1.23.1 k8sbalanceworker1 Ready <none> 3d13h v1.23.1
十一.总结
本篇博客介绍了在 CentOS 7.4 上安装部署 Kubernetes(k8s) 高可用集群的步骤。从安装 Docker 和 Kubernetes 相关工具,部署负载均衡器haproxy,部署etcd集群,初始化主节点,配置网络插件,添加其他主节点和工作节点,部署高可用控制平面,到最后验证集群状态,每个步骤都详细说明了操作方法。
通过搭建高可用的 Kubernetes 集群,可以确保应用程序的稳定性和可靠性。