
本文主要介绍 Windows 环境下搭建 PostgreSQL 的主从逻辑复制,关于 PostgreSQl 的相关运维文章,网络上大多都是 Linux 环境下的操作,鲜有在 Windows 环境下配置的教程,所以本文采用 Windows 环境作为演示系统来进行 PostgreSQL 高可用数据库服务的搭建。
关于 Windows 系统 PostgreSQL 的安装方法可以直接看之前的博客 https://www.cnblogs.com/berkerdong/p/16645493.html
在Windows 环境运行 PostgreSQL 在连接数的配置需要注意以下这个知识点:
由于PostgreSQL所依赖的一些库依赖于user32.dll,后者从内存中一块称为桌面堆(Desktop Heap)的区域中分配内存。桌面堆被分配给了每一个登录的会话,在 Windows 10 以上的操作系统通常一个非交互的会话将会分配给768KB。每个交互登录会话将会分配给20MB的桌面堆,每个postgres进程典型的桌面堆消耗是3.2KB。
当作为Windows服务运行时,因为每个非交互会话将会分配768KBMB的桌面堆,所以大约可以支撑 200-220个连接。
当在命令行方式运行时,因为每个交互登录会话将会分配20MB的桌面堆,所以大约可以支撑 5000-6000个连接。
以上说的值是操作系统默认的值,这个堆分配大小可以通过调整注册表来进行修改,但是此操作需要非常小心,一旦指定的值过大,系统将无法启动,所以不推荐去手动修改这个值。如果想要了解更多这个知识点可以看 微软官方的这个说明:
https://learn.microsoft.com/zh-CN/troubleshoot/windows/win32/user32-kernel32-not-initialize
结合上面的知识点,所以我们在Windows环境下配置 PostgreSQL 的最大连接数时,如果采用 Windows 服务模式运行则配置最大连接数为200比较好,如果需要200个以上的并发连接,则最好采用控制台形式启动运行PostgreSQL,同时结合计算机的可以内存去综合考虑一般100个连接数会消耗 1G内存,所以假设我们电脑内存为8G,考虑到系统本身运行需要2G内存,所以这是 PostgreSQL 的最大连接数配置为500 左右即可。
PostgreSQL控制台运行,启动和停止命令如下:
启动 pg_ctl.exe -D "D:\Software\PostgreSQL\data" start
停止 pg_ctl.exe -D "D:\Software\PostgreSQL\data" stop
-D 的参数 "D:\Software\PostgreSQL\data" 是 PostgreSQL 的数据实例位置
今天我们采用逻辑同步复制来实现主从数据库的配置,首选在主数据库上调整 postgresql.conf 配置文件启用逻辑复制功能
wal_level = logical

配置调整之后需要重新启动主数据库实例。
然后在主数据库对我们需要配置的数据库执行逻辑发布CREATE PUBLICATION p FOR ALL TABLES WITH (publish = 'insert, update, delete, truncate', publish_via_partition_root = false);
其中 p 为这个发布设置的名称,也可以自定义为其它。
然后在从数据库实例上选择我们要用来订阅主实例的数据库,然后执行创建逻辑订阅
CREATE SUBSCRIPTION s CONNECTION 'host=127.0.0.1 port=5432 user=postgres dbname=xxxxx connect_timeout=10 password=xxxxxx' PUBLICATION p WITH (connect = true, enabled = true, copy_data = true, create_slot = true, synchronous_commit = 'remote_apply');
其中 s 为这个订阅设置的名称 'host=127.0.0.1 port=5432 user=postgres dbname=xxxxx connect_timeout=10 password=xxxxxx' 为主库的连接信息
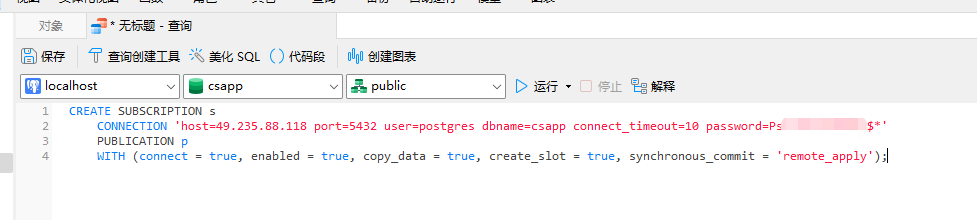
因为我们创建的订阅 synchronous_commit 采用的是 remote_apply 模式,该模式可以理解为同步复制,当客户端像主库提交事务之后,需要等 synchronous_standby_names 总配置的节点全部完成 remote_apply 收到数据之后,主库才会给备库返回事务成功提交的状态,创建好名为 s 的订阅创建之后,我们再次打开 主库的 postgresql.conf 文件进行调整设置
synchronous_standby_names = 's'
调整配置文件之后记得重启主库的数据库实例
这样我们就完成本地 localhost 的 PostgreSQL 实例中 csapp 数据库和 远程服务器上 caspp 数据库的主从配置。
这里要注意的一点是 PostgreSQL 的 逻辑订阅并不会同步DDL操作 ,所以对于数据库的建表等操作是不会进行主从同步的,我们需要手动维护 主从实例数据库上的表结构使其保持一致。
当在主和从数据库都创建完成表之后需要在从库上执行以下刷新订阅的 SQL,每次主库新增或者删除了表,从库都需要执行这个操作。
ALTER SUBSCRIPTION s REFRESH PUBLICATION WITH (copy_data = true);
然后我们在主库的数据库表中进行数据操作,所有的操作就会被同步到 从库的数据表中。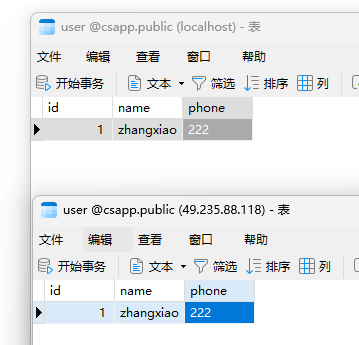
下面介绍如果想要删除发布设置和订阅设置的操作
在主库执行
SELECT * FROM pg_publication 可以查询当前主库的所有发布信息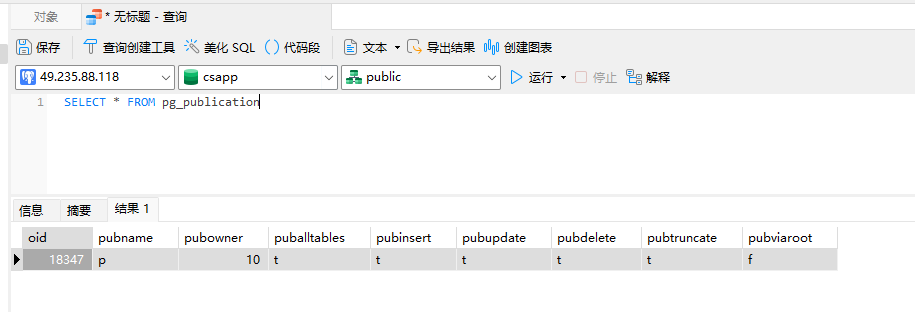
DROP PUBLICATION p 删除名字为 p 的发布信息
在从库执行:
SELECT * FROM pg_subscription 可以查询当前从库的所有订阅信息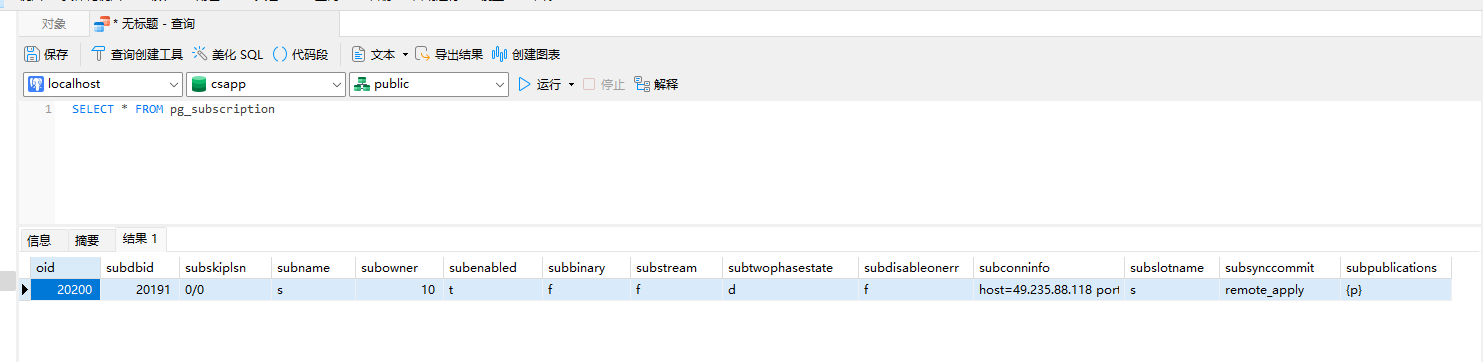
DROP SUBSCRIPTION s 删除名字为 s 的订阅信息
然后记得去主库的 postgresql.conf 找到 synchronous_standby_names 删除 s 节点的配置
#synchronous_standby_names='s'
如果只有一个从节点的,则直接添加 # 对 synchronous_standby_names 进行注释即可
当有多个从库订阅的时候synchronous_standby_names 还可以采用以下配置模式
synchronous_standby_names='s1' 代表s1备机返回就可以提交。
synchronous_standby_names='FIRST 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中前两个s1和s2返回主库就可以提交。
synchronous_standby_names='ANY 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中任意两个备机返回主库就可以提交。
synchronous_standby_names='ANY 2 (*)' 代表所有备机中任意两个备机返回主库就可以提交。
synchronous_standby_names='*' 代表匹配任意主机,也就是任意主机返回就可以提交。
这里有一点需要注意,这是 PostgreSQL 在同步复制时的一个已知问题,假设 一个主库,一个备库 s1,采用同步模式,然后 synchronous_standby_names 配置为 synchronous_standby_names='s1',虽然从配置上来看似乎数据必须要提交到s1并且s1成功响应之后,主库才会为客户端返回事务操作成功的响应,但是实际情况下,当备库挂掉的情况下,主库在收到一个事务操作时,在等待 s1 备库的返回时因为 s1库已经挂掉了所以这个操作肯定会超时,当主备节点通信超时之后,主节点还是会像客户端返回事务成功提交的命令,客户端的操作还是会成功,同时因为每个事务操作都要经历这个超时的流程,所以客户端的所有事务操作都会相对很卡。
比如每个 insert 都会经过主库和备库的这个通信超时过程,所以每个 insert 动作都变成了大约30秒次才能完成,就会导致应用程序很卡。这时候就相当于主库在以(很卡的)独立模式运行,这个情况在备库重新上线之后就会恢复正常(如果备库短期之内无法恢复,可以调整主库的 synchronous_standby_names设置 移除对于s1备库的事务等待验证,变为单库运行模式重启实例之后也就不会卡了),但是要注意当主库脱离备库独立运行时,如果这个时候主库发生灾难比如硬盘坏掉,则就会产生数据丢失。所以建议至少有2个备库来提升保障级别
至此 Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务 就讲解完了,有任何不明白的,可以在文章下面评论或者私信我,欢迎大家积极的讨论交流,有兴趣的朋友可以关注我目前在维护的一个 .NET 基础框架项目,项目地址如下
https://github.com/berkerdong/NetEngine.git
https://gitee.com/berkerdong/NetEngine.git