本文介绍了分布式系统监控的三种主要内容:Logging(日志)、Tracing(调用链)、Metrics(离散数据点)。强调了Prometheus在Metrics和健康检查方面的优势,详细阐述了Prometheus的架构、优点、基本概念、Metrics种类、采集形式、PromQL查询语言及Alertmanager告警系统。通过实践指南展示了如何在本地环境部署Prometheus,结合Grafana进行数据可视化,并配置Alertmanager进行告警。旨在帮助读者全面了解Prometheus及其在监控系统中的应用。
如果你是分布式系统的开发人员或者运维人员,肯定要了解系统监控的手段,有哪些监控的内容。如下有三种监控内容:

Logging:日志,离散事件,一般是文本的,最常用的也是比较好用的一种方式
Tracing : 调用链,一般是请求,一般是跟踪一个请求从网关一直到后端某服务,最终返回给客户端,可以参考:微服务调用链基本原理与使用
Metrics:离散的数据点,最终存储到数据库里面,一般是一个数字,并且可以进行计算。
除此之外,还有对系统进行健康检查,healthchecks。Prometheus主要是进行Metrics和健康检查进行监控。
监控的应用场景
| Metrics | Logging | Tracing | |
|---|---|---|---|
| 研发成本 | 中 | 低 | 高 |
| 运维成本 | 低 | 高(业务量增大,扩容,调优) | 中 |
| 出问题后响应能力 | 高(很快效应) | 中 | 低(主要用于排查问题) |
| 查问题 | 低 | 中 | 高 |
参考:Go for Industrial Programming

当出现问题的时候,我们主要去看日志,看Tracing,找到问题所在
当健康检查出现问题的时候,通过Metrics进行告警是比较灵敏的,Metrics可以对监控进行如下分层
系统层面的metrics,cpu,内存,io等信息,一般是运维处理
应用层面,出错率,请求延迟等,一般是开发处理
业务层Metrics则是转化率,下单率,一般产品与运营人员关注
Metrics监控架构
一般主要有推和拉两种方式:
推,则是在监控主机上安装agent,定期的上报系统信息
拉,比较简单,但是对监控服务器有很大的压力

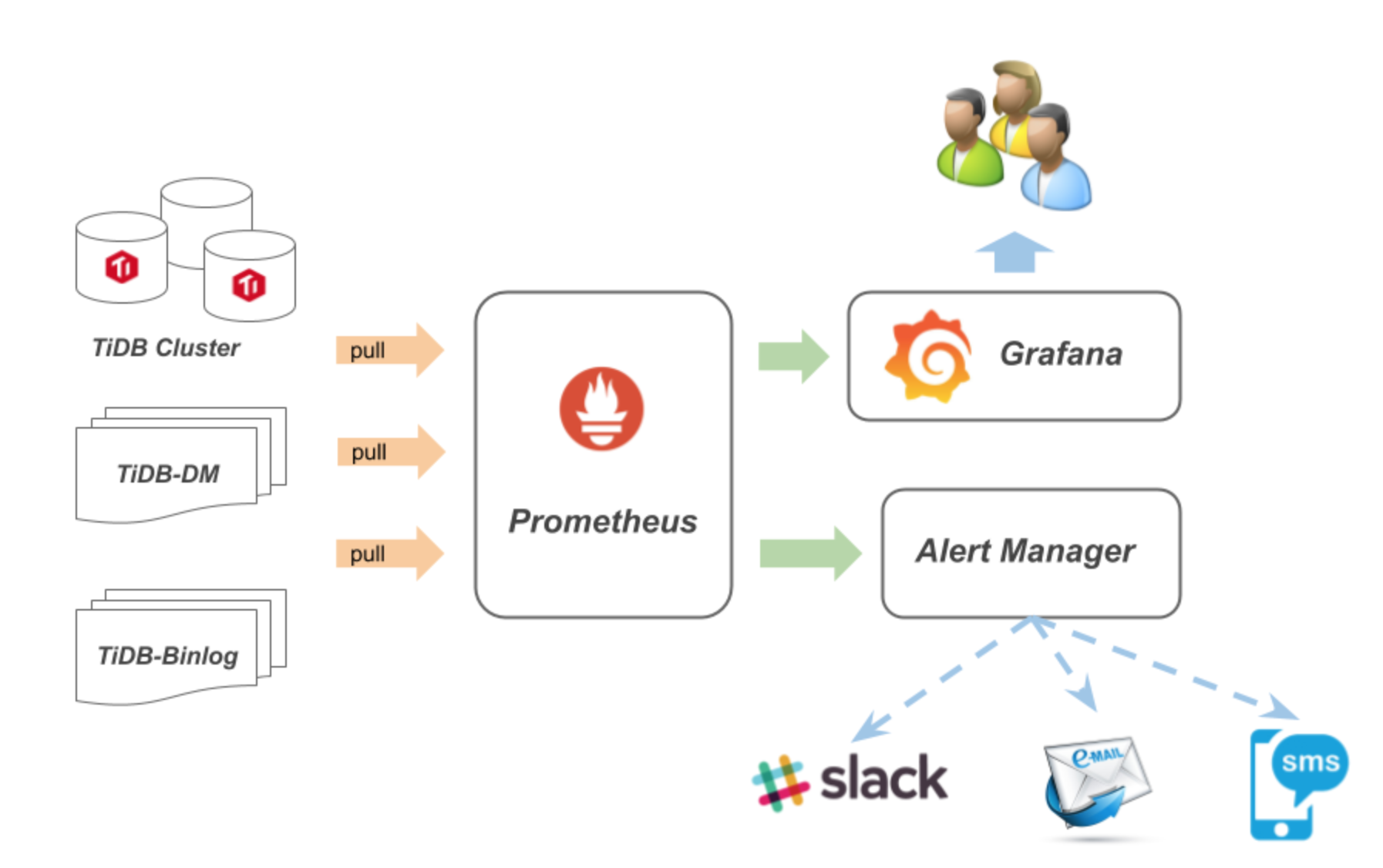
对于Prometheus一般采用如下监控架构:
将TiDB转换为我们的其它业务服务器
Prometheus简介
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。它本质上是一个数据库,时间序列的数据库,Soundcloud研发。采用pull模式,支持黑盒与白盒。是推进践行DevOPS的一个很好的方式。
相比于传统监控系统Prometheus具有以下优点:
支持各种语言的客户端,支持各种exports。
性能强劲,支持百万的序列。
社区生态丰富,在github上已经2万多start,2019.06.16
易于管理,可扩展,强大的查询语言PromQL,易于集成,可视化,开放性等等
Prometheus在其官网上给出了架构图,主要包含Prometheus的生态组件:

Prometheus基本概念
Metrics种类:
Counter计数器,始终增加的,比如Http请求数,下单数
Gauge(测量仪):当前值的一次快照,比如磁盘使用率
Histogram(直方图):区间的分布情况,比如某个年龄段有多少人
Summary(汇总):根据样本统计出百分位
Metrics形式:
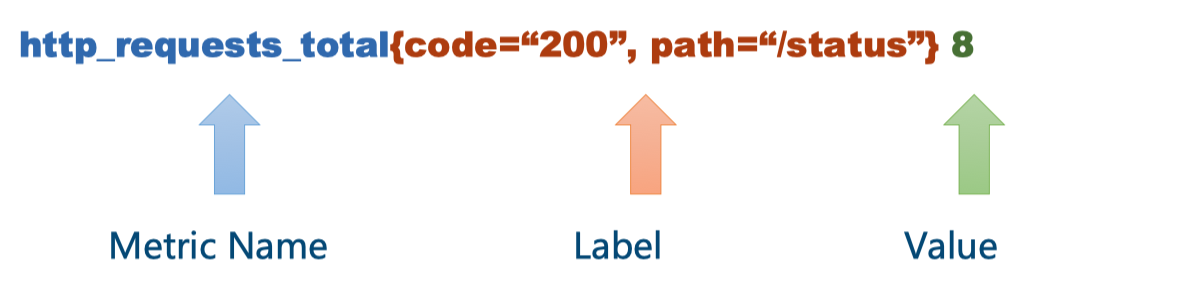
<metric name>{<label name>=<label value>, ...}比如名称为http_requests_total的metric,标签有两个code="200",path="/status",最终存储的值为8。
Metrics采集形式:
直接采集,Prometheus与要采集的指标直接打交道,比如Spring Boot已经提供了Metrics,可以直接用
简接采集,没有提供metrics,需要exporter来与产品和Prometheus打交道,exporter相当于适配器。prometheus提供了很多exporter
PromeQL:
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。
Alertmanager:
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:

Prometheus安装及使用
1 去官网下载prometheus的安装包,或者使用docker都行,安装方式灵活。下载地址:https://prometheus.io/download/ , 我用的是Mac系统,根据自己的系统进行选择

2 做一个简单的配置,作为对prometheus实际使用的了解,去掉大部分的注释之后
global: scrape_interval: 15s evaluation_interval: 15s rule_files: # - "first.rules" # - "second.rules" scrape_configs: - job_name: prometheus static_configs: - targets: ['localhost:9090']
scrape_interval控制抓取metric的间隔时间,可以在targets中覆盖掉global的配置
evaluation_interval,评估rule的时间,prometheus会使用rules来创建新的时间序列和报警
scrape_configs,配置prometheus要监控的资源
3 启动prometheus,然后查看是否正常运行。
./prometheus --config.file=prometheus.yml
然后访问:
4 在http://localhost:9090/graph中,grath的标签栏查看图表,在表达式哪里输入表达式查看效果:

Prometheus实践指南
在github上,有架构师杨波提供的几节prometheus的实验项目地址:https://github.com/spring2go/prom_lab
1 首先打开http_simulate项目,查看里面的代码,核心代码位于ActivitySimulator。
通过/spike/{mode}请求设置是否开启流量高峰模拟
通过/error_rate/{error_rate}模拟内部的http状态码有多少错误率
内部有一个线程池不断的模拟请求,至于内部的Counter,Histogram类,我们上文已经提到过
2 启动项目,进行模拟
访问:http://localhost:8080/prometheus 查看当前prometheus的状态,

在prometheus.yml配置文件中增加如下job:
- job_name: 'http-simulator' metrics_path: /prometheus static_configs: - targets: ['localhost:8080']
3 启动prometheus,进行查询,之前我们有进行过简单的查询,这次比如要查询:
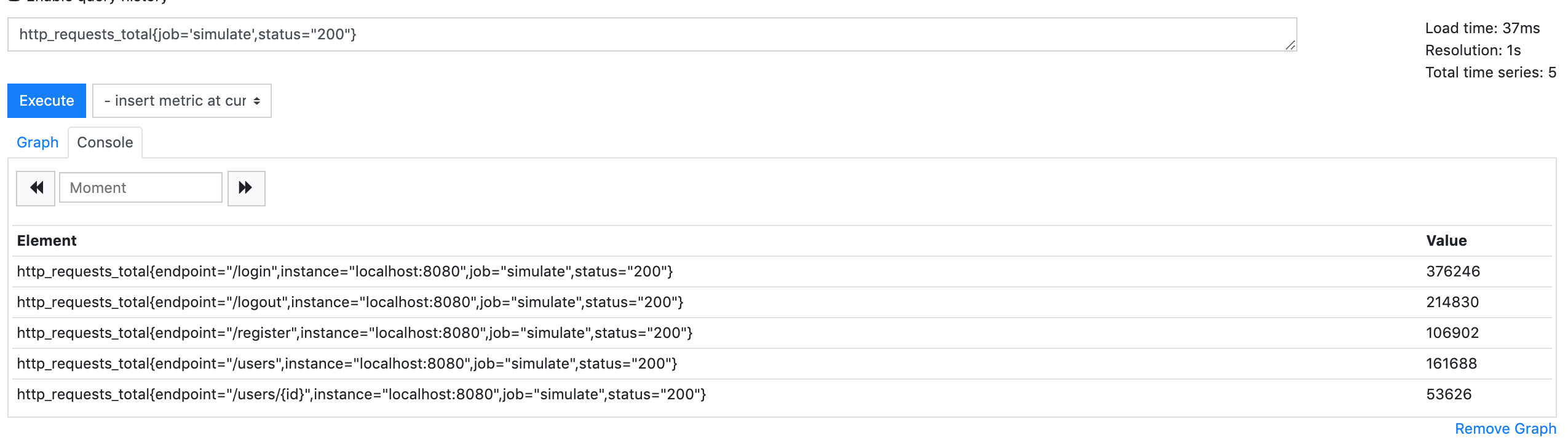
// 查询名称为http_requests_total的metric,并且label为job='simulate',status="200"
http_requests_total{job='simulate',status="200"}从graph也可以看得出来效果,metric的label在我们的代码中配置:prometheus的promQL内部提供了函数方便使用:如rate,increase等,参考:https://prometheus.io/docs/prometheus/latest/querying/functions/#rate
4 prometheus与Grafana进行结合,架构如图,记得要安装Grafana。
下载地址:https://grafana.com/grafana/download

grafana默认地址:http://localhost:3000,默认账号密码:admin,admin

Grafana本身不存储数据,只负责展示,需要添加数据源。Grafana支持很多种类型的数据源,这次我们要选择是的prometheus的数据源,如果没有对prometheus做特殊修改,采用默认配置即可,注意ip地址要填写正确。

5 配置Grafana图表,添加Dashboard,然后添加图表。Grafana做的实在是人性化,不需要去教怎么去添加东西,只需要自己摸索下常见的选项,多点击几下就知道怎么用了。最后记得点击保存。
Grafana文档:https://grafana.com/docs/



6 配置报警,AlertManager可以用多种方式安装。
AlertManager介绍地址:https://github.com/prometheus/alertmanager
配置alertmanager.yml:
global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:465' smtp_from: 'aihehe123@foxmail.com' # 自己去QQ的客户端去生成授权码,password为QQ的授权码 smtp_auth_username: 'aihehe123@foxmail.com' smtp_auth_password: 'xxx' # 记得设置为false,不然会报错 smtp_require_tls: false route: # group_by: ['alertname'] # group_wait: 10s group_interval: 1m repeat_interval: 1m receiver: 'mail-receiver' receivers: - name: 'mail-receiver' email_configs: - to: 'aihehe123@foxmail.com'
然后再新建报警的规则配置文件:simulator_alert_rules.yml
# 第一个规则代表simulate服务器停止了
groups:
- name: simulator-alert-rule
rules:
- alert: HttpSimulatorDown
expr: sum(up{job="simulate"}) == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Simulator Stoped"
description: "stopped"
# 第二个规则代表服务器500的错误码比例大于2%了
- alert: ErrorRateHigh
expr: sum(rate(http_requests_total{job="simulate", status="500"}[5m])) / sum(rate(http_requests_total{job="simulate"}[5m])) > 0.02
for: 1m
labels:
severity: major
annotations:
summary: "High Error Rate detected"
description: "Error Rate is above 2% (current value is: {{ $value }}"最后配置prometheus.yml,增加告警服务器地址:
# Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 127.0.0.1:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "simulator_alert_rules.yml"
7 启动AlertManager。重启prometheus服务器。
在http://localhost:9090/config 看看配置是否生效
看看是否有告警信息:http://localhost:9090/alerts

8 停止simulate服务器,查看报警是否生效。最终看到有效效果,成功收到报警信息


9 停掉Promethus,停掉Grafana,停掉Alertmanager,至此实验完成。
最后
在本篇文章里:
介绍了一些监控的种类与特点
引入Prometheus,介绍Prometheus的架构与概念
实战部署Prometheus + Grafana + AlertManager,验证Prometheus的强大功能
最后希望能帮助到大家
参考
注:
本文独家发布自金蝶云社区